






You know that when attribution models (MTA, last-click, platform reports) often over-credit ads, incrementality can reveal the true lift from your spend. So, how do you measure incrementality?
This guide walks through the most common incrementality testing methods, explains how they work, and breaks down when each one is best used. By the end, you’ll know which test design fits your goals, budget, and data maturity — plus how incrementality pairs with MMM and MTA in a modern measurement strategy.
Incrementality testing shows the causal impact of a channel, campaign, ad set, or marketing tactic by comparing:
The difference in outcomes between these groups is your incremental lift. In other words, this is the amount of performance truly caused by advertising, not noise or unrelated influences like:
In incrementality testing, how you divide users or regions into treatment vs. control is a key design choice. You might use simple randomization, weighting, or time-series modeling to build a fair comparison.
This differs from a classic A/B test. In a typical A/B test, you compare two creative variations (ad A vs. ad B or page A vs. page B) shown to different groups. The goal is to see which version performs better.
Incrementality testing instead asks: “What would have happened if we showed no ads at all?” It tests whether the channel or campaign drives any incremental lift, not just which creative wins.
Attribution is different again. Traditional and multi-touch attribution track how individual users interact with your ads — which ad they clicked, which channel they came from, how many touchpoints they had before converting.
Incrementality doesn’t accept those credits at face value. It focuses only on the sales that wouldn’t have happened without ad exposure, filtering out organic sales, returning customers, and other noise.
What are incrementality experiments? The table below shows the different types of marketing experimentation, followed by additional methods and in-depth explanations.
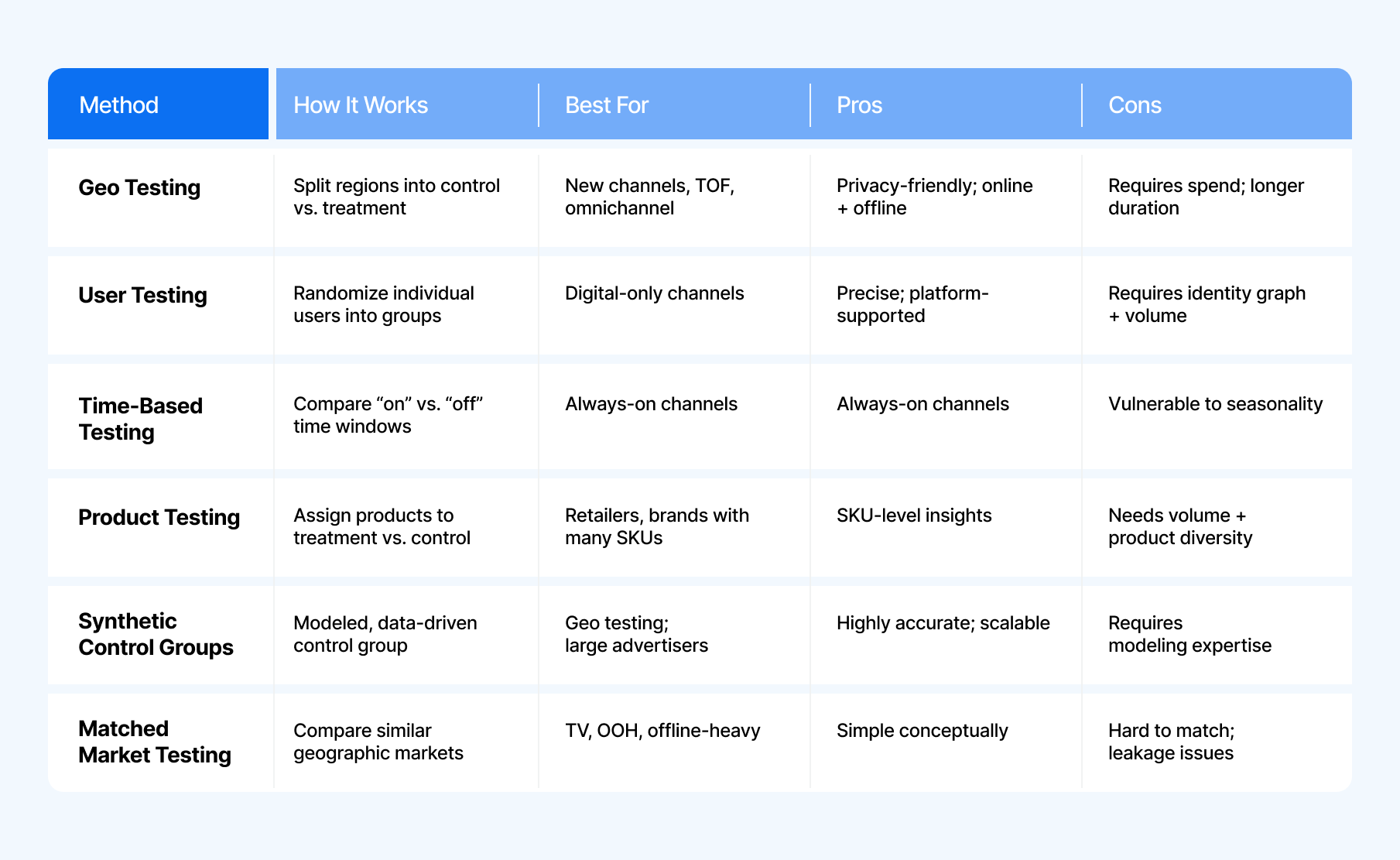
Geo testing (aka geo experiments, geo-based experiments or Meta’s “GeoLift”) split audiences by geography — like cities, states, or postal codes.
You run your campaign in the treatment regions and hold out spend in the controls. After the test, you compare aggregate sales across both groups.
Here is a marketing experiment example:
You want to validate whether your new YouTube campaign drives incremental sales. You advertise in 10 treatment DMAs and exclude 10 matched DMAs. After 4–6 weeks, the lift shows YouTube is more incremental than attribution suggested.
User-level experiments randomize individuals into control and treatment groups.
A conversion lift test is typically a user-level holdout / platform-managed incrementality test. Platforms like Meta, Google, TikTok, and large retailers can sometimes run these tests because they have robust identity graphs.
One drawback of this marketing experimentation is the potential for selection bias, where certain types of users may be more likely to respond to marketing interventions. Privacy regulations must be carefully followed.
Best For:
There are a few user-specific avenues you could head down.
This is the simplest method for user testing. You randomly assign X% of your audience to the control group and withhold ads from them.
In this method, control and treatment users are assigned but not guaranteed to see (or not see) ads. It’s a lower-cost option, but also produces more noise.
Both treatment and control groups see ads but the control group sees PSAs or non-branded ads instead.
This ensures both groups receive impressions, and is best used across open and closed environments when no cross-site user IDs are available. However, you still pay to serve non-branded PSAs, and results may be biased.
In a ghost ad, the ad platform runs an auction for an impression but intentionally withholds the ad from the control group. The system still logs this “ghost” impression, allowing that user to be included in the measurement data.
This works best in closed environments where the auction process is fully visible, like owned inventory like social channels.
This is the open-web version of ghost ads. Ghost bids refer to users who met your campaign’s targeting criteria and were active on the programmatic network, but whose impressions weren’t won in the auction.
These users are passively tracked and used to form your control group. It’s highly accurate yet complex to set up.
This method compares performance before, during, and after the marketing campaign experiment. Time-based tests should be used sparingly and usually as a last resort.
While it is useful for always-on channels, it has a lower statistical power.
Example: Uber’s U.S. & Canada Rider Performance Marketing Analytics team suspected that week-over-week CAC fluctuations were driven more by seasonality than Meta ads.
They paused Meta ads for several months (time-based) and monitored business performance over time. The result: no measurable negative impact, which allowed Uber to reallocate roughly $35M annually into more effective channels.
This method is exactly what it sounds like. Instead of testing audiences, you divide products into treatment and control groups.
This method shines when product assortment is large and customers frequently buy across categories. However, cross-product halo effects can complicate the analysis.
Synthetic controls replace real control geographies with modeled controls built from historical + cross-sectional data. Instead of picking “similar regions,” a model generates an expected baseline.
Synthetic controls are increasingly becoming the standard for modern geo experiments (and a core part of how advanced measurement platforms run lift tests).
Finding truly comparable geographies is often impossible. Synthetic controls solve for:
The alternative approach to synthetic controls is called matched market testing, whereby similar geographies are selected each as treatment and control.
This traditional method compares performance:
It’s very hard to get truly matched markets and leakage is common, so most modern teams prefer synthetic controls.
Incrementality testing tools are best for:
But different situations call for different test designs. Below are some marketing experiment examples to help you decide:
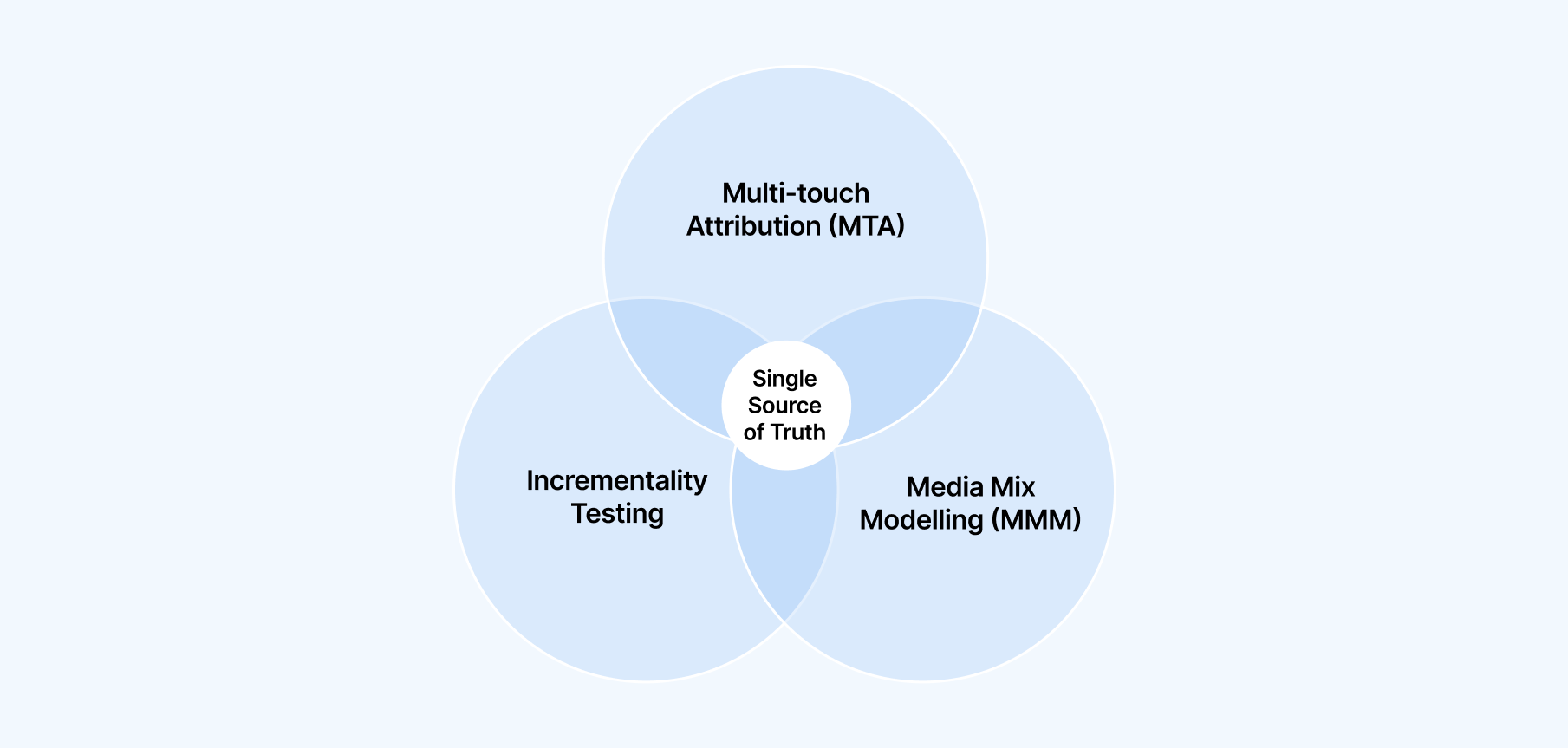
Incrementality testing is powerful, but it’s only one layer of ad campaign effectiveness measurement.
The three most widely used measurement approaches today are:
As seen above, every incrementality method has potential downsides: Geo tests require volume, user tests require IDs, matched markets can mislead, and time-based tests risk seasonality.
Together, these methods “triangulate” reality — helping you reconcile conflicting signals and move with confidence.
This triangulation is the foundation of modern Unified Measurement.
If your brand is feeling blind spots, conflicting attribution, or uncertainty around which channels truly drive new revenue, you’re not alone — and you don’t need to juggle three disconnected tools to find the answer.
Compass, Triple Whale's unified measurement system, combines attribution, MMM, and incrementality testing methods into one place — complete with AI Agents that reconcile disagreements and surface your next best action.
Ready to test what’s truly working in your marketing? Schedule a demo.
If your campaign drives thousands of impressions/day, you can finish in 2–4 weeks for user-level tests, or 4–6 weeks for geo tests. If you have low volume, add 1–3 more weeks.
When you’re measuring channels or campaigns that don’t have reliable user-level tracking — like TikTok, CTV, podcasts, or offline media — because geography provides a clean way to isolate causal impact.
You need enough data for the test to reach statistical significance in both the treatment and control groups, typically meaning hundreds to thousands of conversions per group.
You know that when attribution models (MTA, last-click, platform reports) often over-credit ads, incrementality can reveal the true lift from your spend. So, how do you measure incrementality?
This guide walks through the most common incrementality testing methods, explains how they work, and breaks down when each one is best used. By the end, you’ll know which test design fits your goals, budget, and data maturity — plus how incrementality pairs with MMM and MTA in a modern measurement strategy.
Incrementality testing shows the causal impact of a channel, campaign, ad set, or marketing tactic by comparing:
The difference in outcomes between these groups is your incremental lift. In other words, this is the amount of performance truly caused by advertising, not noise or unrelated influences like:
In incrementality testing, how you divide users or regions into treatment vs. control is a key design choice. You might use simple randomization, weighting, or time-series modeling to build a fair comparison.
This differs from a classic A/B test. In a typical A/B test, you compare two creative variations (ad A vs. ad B or page A vs. page B) shown to different groups. The goal is to see which version performs better.
Incrementality testing instead asks: “What would have happened if we showed no ads at all?” It tests whether the channel or campaign drives any incremental lift, not just which creative wins.
Attribution is different again. Traditional and multi-touch attribution track how individual users interact with your ads — which ad they clicked, which channel they came from, how many touchpoints they had before converting.
Incrementality doesn’t accept those credits at face value. It focuses only on the sales that wouldn’t have happened without ad exposure, filtering out organic sales, returning customers, and other noise.
What are incrementality experiments? The table below shows the different types of marketing experimentation, followed by additional methods and in-depth explanations.
Geo testing (aka geo experiments, geo-based experiments or Meta’s “GeoLift”) split audiences by geography — like cities, states, or postal codes.
You run your campaign in the treatment regions and hold out spend in the controls. After the test, you compare aggregate sales across both groups.
Here is a marketing experiment example:
You want to validate whether your new YouTube campaign drives incremental sales. You advertise in 10 treatment DMAs and exclude 10 matched DMAs. After 4–6 weeks, the lift shows YouTube is more incremental than attribution suggested.
User-level experiments randomize individuals into control and treatment groups.
A conversion lift test is typically a user-level holdout / platform-managed incrementality test. Platforms like Meta, Google, TikTok, and large retailers can sometimes run these tests because they have robust identity graphs.
One drawback of this marketing experimentation is the potential for selection bias, where certain types of users may be more likely to respond to marketing interventions. Privacy regulations must be carefully followed.
Best For:
There are a few user-specific avenues you could head down.
This is the simplest method for user testing. You randomly assign X% of your audience to the control group and withhold ads from them.
In this method, control and treatment users are assigned but not guaranteed to see (or not see) ads. It’s a lower-cost option, but also produces more noise.
Both treatment and control groups see ads but the control group sees PSAs or non-branded ads instead.
This ensures both groups receive impressions, and is best used across open and closed environments when no cross-site user IDs are available. However, you still pay to serve non-branded PSAs, and results may be biased.
In a ghost ad, the ad platform runs an auction for an impression but intentionally withholds the ad from the control group. The system still logs this “ghost” impression, allowing that user to be included in the measurement data.
This works best in closed environments where the auction process is fully visible, like owned inventory like social channels.
This is the open-web version of ghost ads. Ghost bids refer to users who met your campaign’s targeting criteria and were active on the programmatic network, but whose impressions weren’t won in the auction.
These users are passively tracked and used to form your control group. It’s highly accurate yet complex to set up.
This method compares performance before, during, and after the marketing campaign experiment. Time-based tests should be used sparingly and usually as a last resort.
While it is useful for always-on channels, it has a lower statistical power.
Example: Uber’s U.S. & Canada Rider Performance Marketing Analytics team suspected that week-over-week CAC fluctuations were driven more by seasonality than Meta ads.
They paused Meta ads for several months (time-based) and monitored business performance over time. The result: no measurable negative impact, which allowed Uber to reallocate roughly $35M annually into more effective channels.
This method is exactly what it sounds like. Instead of testing audiences, you divide products into treatment and control groups.
This method shines when product assortment is large and customers frequently buy across categories. However, cross-product halo effects can complicate the analysis.
Synthetic controls replace real control geographies with modeled controls built from historical + cross-sectional data. Instead of picking “similar regions,” a model generates an expected baseline.
Synthetic controls are increasingly becoming the standard for modern geo experiments (and a core part of how advanced measurement platforms run lift tests).
Finding truly comparable geographies is often impossible. Synthetic controls solve for:
The alternative approach to synthetic controls is called matched market testing, whereby similar geographies are selected each as treatment and control.
This traditional method compares performance:
It’s very hard to get truly matched markets and leakage is common, so most modern teams prefer synthetic controls.
Incrementality testing tools are best for:
But different situations call for different test designs. Below are some marketing experiment examples to help you decide:
Incrementality testing is powerful, but it’s only one layer of ad campaign effectiveness measurement.
The three most widely used measurement approaches today are:
As seen above, every incrementality method has potential downsides: Geo tests require volume, user tests require IDs, matched markets can mislead, and time-based tests risk seasonality.
Together, these methods “triangulate” reality — helping you reconcile conflicting signals and move with confidence.
This triangulation is the foundation of modern Unified Measurement.
If your brand is feeling blind spots, conflicting attribution, or uncertainty around which channels truly drive new revenue, you’re not alone — and you don’t need to juggle three disconnected tools to find the answer.
Compass, Triple Whale's unified measurement system, combines attribution, MMM, and incrementality testing methods into one place — complete with AI Agents that reconcile disagreements and surface your next best action.
Ready to test what’s truly working in your marketing? Schedule a demo.
If your campaign drives thousands of impressions/day, you can finish in 2–4 weeks for user-level tests, or 4–6 weeks for geo tests. If you have low volume, add 1–3 more weeks.
When you’re measuring channels or campaigns that don’t have reliable user-level tracking — like TikTok, CTV, podcasts, or offline media — because geography provides a clean way to isolate causal impact.
You need enough data for the test to reach statistical significance in both the treatment and control groups, typically meaning hundreds to thousands of conversions per group.

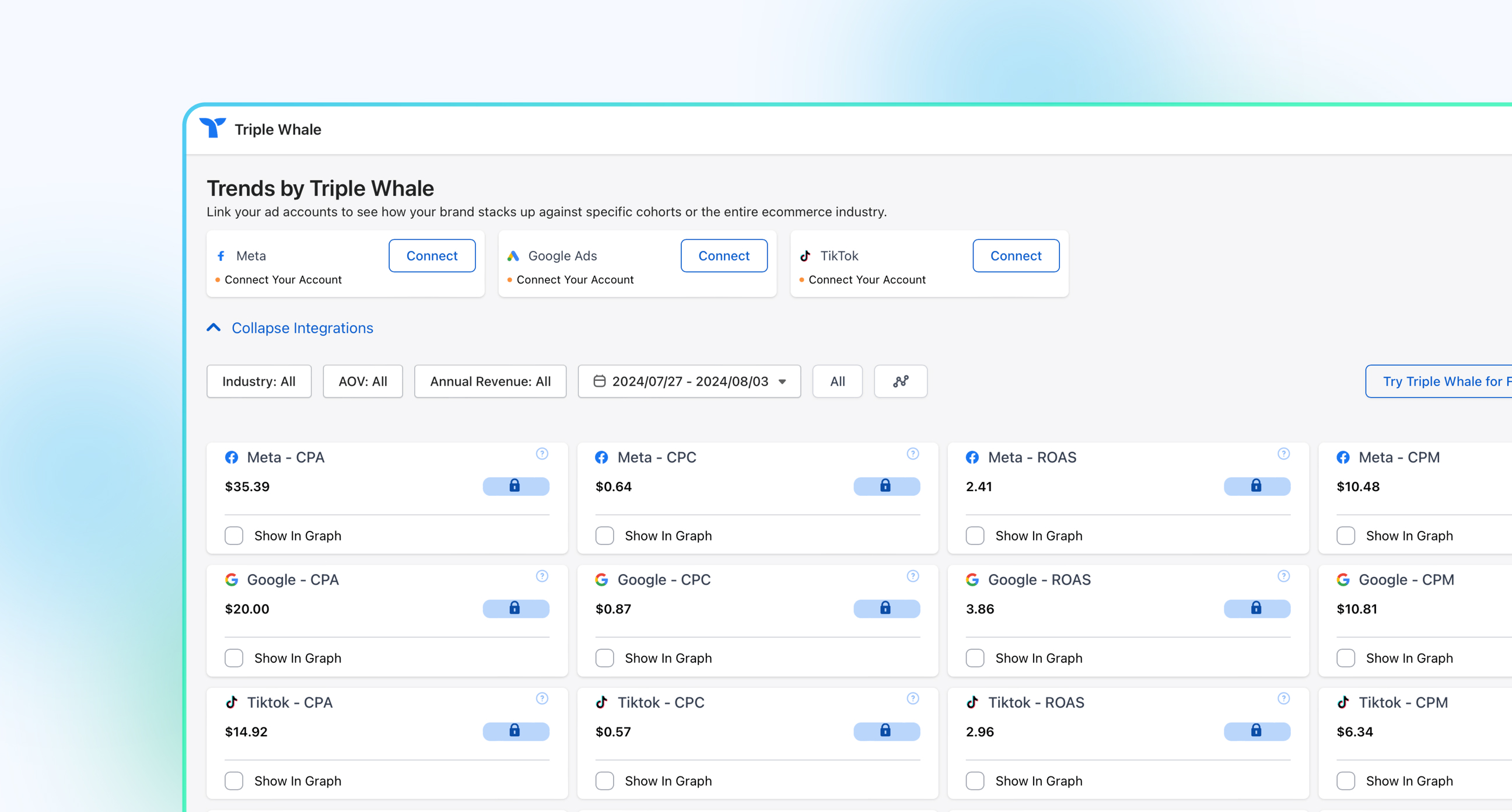
Body Copy: The following benchmarks compare advertising metrics from April 1-17 to the previous period. Considering President Trump first unveiled his tariffs on April 2, the timing corresponds with potential changes in advertising behavior among ecommerce brands (though it isn’t necessarily correlated).




.webp)

.webp)

.png)



.png)
